Second order point statistics are homogeneity measures of how uniformly the points are distributed within the observation window. They are used to study data locations in relation to other data points.
Location of pharmacies in a part of Madrid city:
In[2]:=
locs=GeoPosition;
Create with the observation region inferred from the data points:
In[3]:=
data=SpatialPointData[locs]
Out[3]=
SpatialPointData
Visualize the data:
In[3]:=
GeoListPlot[data]
Out[3]=
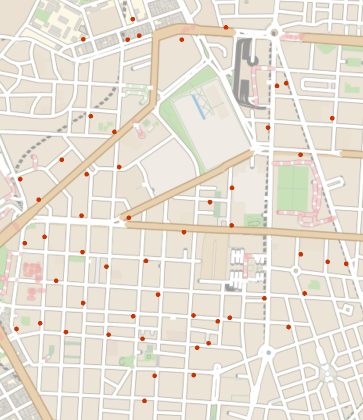
Test if the locations are random:
In[4]:=
SpatialRandomnessTest[data,"TestDataTable"]
Out[4]=
Statistic | P-Value | |
ModifiedChiSquare | 6.74657 | 0.663486 |
In[5]:=
SpatialRandomnessTest[data,"TestConclusion"]
Out[5]=
The null hypothesis that the data exhibits complete spatial randomness is not rejected at the 5 percent level based on the ModifiedChiSquare test.
So it looks like the locations are random, but are they arbitrarily close to each other? For the answer we compute :
In[4]:=
nng=NearestNeighborG[data]
Out[4]=
PointStatisticFunction
Compute maximum radius for the point statistics function:
In[5]:=
maxR=nng["MaxRadius"]
Out[5]=
Maximum radius magnitude in meters:
In[6]:=
maxRm=QuantityMagnitude[maxR,"Meters"]
Out[6]=
324.788
Visualize:
In[10]:=
DiscretePlot[nng[Quantity[x,"Meters"]],{x,0,maxRm,maxRm/100},AxesLabel->{"m"}]
Out[10]=
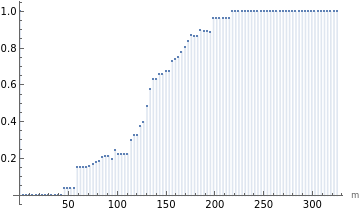
So the plot of the of the data indicates that pharmacies cannot be arbitrarily close to each other. The limiting distance is called hardcore radius and such data can be modelled by a :
In[11]:=
eproc=EstimatedPointProcess[data,HardcorePointProcess[μ,r,2]]
Out[11]=
HardcorePointProcess,,2
Estimated hardcore radius is:
In[12]:=
r=UnitConvert[eproc[[2]],"Meters"]
Out[12]=
Since the pharmacies cannot be arbitrarily close to each other we can ask what is the expected number of pharmacies within given distance from a given pharmacy - that is how big is the competition within the given radius. This can be answered using another point statistics function - :
In[7]:=
funK=RipleyK[data]
Out[7]=
PointStatisticFunction
The product of the value of at and the mean point density gives the expected number of points within distance of a typical point, not counting the point itself:
r
r
In[9]:=
DiscretePlot[funK[Quantity[x,"Meters"]]*MeanPointDensity[data],{x,0,maxRm,maxRm/100},AxesLabel->{"m"}]
Out[9]=
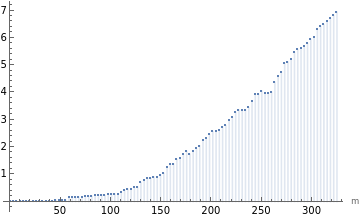
What is the radius within which the expected number of pharmacies is at least 1?
In[11]:=
SelectFirst[Table[{k,funK[Quantity[k,"Meters"]]*MeanPointDensity[data]},{k,100,200}],(Last[#]>=1&)]
Out[11]=
{150,1.02703}
The expected number of pharmacies is at least 1 within the radius of at least 149 meters.
Now let’s compute the probability of encountering a pharmacy within given distance starting from a random location in the observation region which is not a point of the data. The point statistics to do so is :
In[12]:=
esF=EmptySpaceF[data]
Out[12]=
PointStatisticFunction
Value of at gives exactly the probability of finding a point within distance of an arbitrary location which is typically not a point of data set:
r
r
In[14]:=
DiscretePlot[esF[Quantity[x,"Meters"]],{x,0,maxRm,maxRm/100},AxesLabel->{"m"}]
Out[14]=
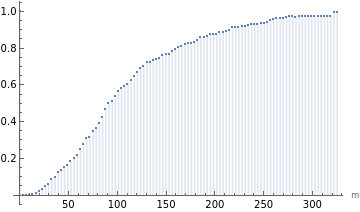
The probability of encountering a pharmacy within 100 meters of a random location in the observation region is:
In[15]:=
esF[Quantity[100,"Meters"]]
Out[15]=
0.557828